
Hello Everyone!
The main part of this post is not this post, but a piece of python-code (and a folder structure alongside). The code will give you an example of how to crawl for desired internet-pages and parse your relevant text-passages out of them. Hopefully, it can also serve as a direct blueprint for some your own projects in the future. There are also extensive comments within the code itself.
What are we doing here then? You need to have python installed in order to open and utilize the content I have so warmly talked about above! So let’s go do that.
Downloading Python
All I am doing here worked for me using Windows. If you run into difficulties, please google some Youtube-tutorials for your operating system.
First visit the download section on the python page: https://www.python.org/downloads/. That should look like this:
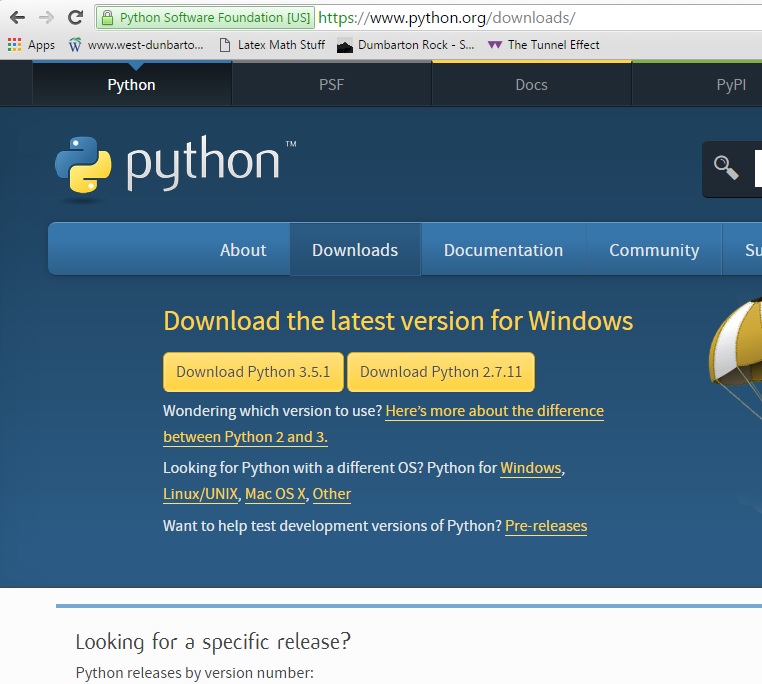
There will be differing opinions on this, but I suggest to download version 2.7.11. So you should click the right-hand side golden button.
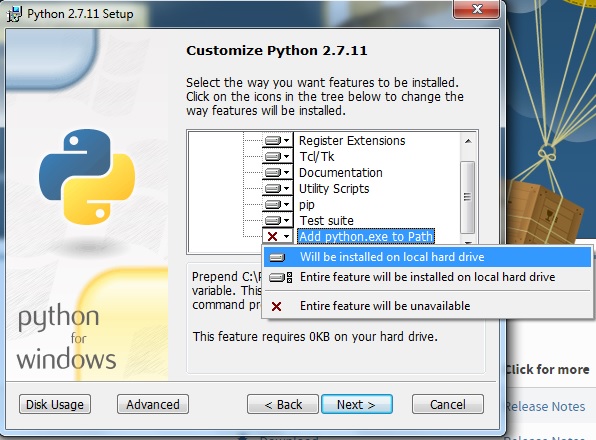
Then follow the basic install procedure: Go to the downloaded setup-file, run it and then next-agree-next-agree-next-… ATTENTION: When going through the installation process, pay attention for the section named “Customize Python 2.7.11”. Looks like this:

There should be a window containing a small directory-tree. If all nodes in the tree show gray boxes, just continue with your next-agree-strategy. If, however, there is one node, named “Add python.exe to Path” that contains a red cross. Pay attention here! If that is the case, click on the little triangle next to the cross and select “Will be installed on local hard drive”.
The result should look like this:
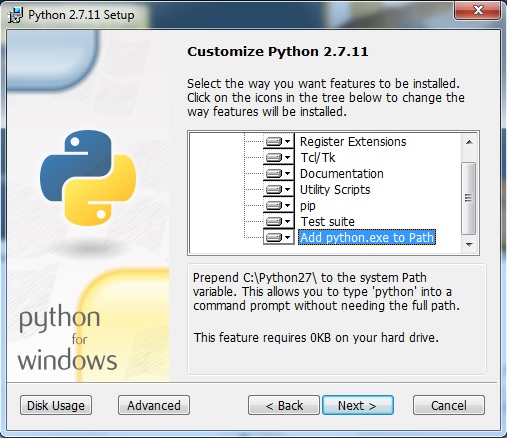
If you succeeded in that, resume your next-agree-routine until your done with the setup.
Congratulations! You have downloaded python!
Now just wait for the workshop to explain how to use it!